


算法简介
在开发前我们先来熟悉一下相似度计算过程中会用到算法的原理吧。
1. 余弦相似度(Cosine Similarity)
原理
余弦相似度用于衡量两个向量之间的夹角余弦值,范围为 [-1, 1],通常用于文本、用户画像匹配等领域。
公式如下:
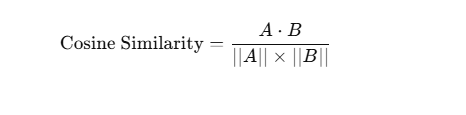
其中:
- ( A \cdot B ) 表示向量 A 和 B 的点积
- ( ||A|| ) 和 ( ||B|| ) 是 A 和 B 的模(L2 范数)
当 值接近 1,说明向量很相似;当 接近 0,说明几乎无关;当 接近 -1,说明完全相反。
适用场景
✅ 文本匹配(NLP):计算两个文本的相似度(TF-IDF + 余弦相似度)
✅ 推荐系统:用户画像匹配,如用户 A 和用户 B 的兴趣相似度
✅ 图像检索:计算图像特征向量的相似度
Python 实现
import numpy as np
def cosine_similarity(A, B):
return np.dot(A, B) / (np.linalg.norm(A) * np.linalg.norm(B))
# 示例:用户 A 和 B 的特征向量
A = np.array([1, 2, 3])
B = np.array([2, 3, 4])
print(cosine_similarity(A, B)) # 输出相似度
2. 高斯算法(Gaussian Function / Gaussian Kernel)
原理
高斯算法通常指 高斯函数(Gaussian Function) 或 高斯核(Gaussian Kernel),用于平滑数据、计算概率密度,或者作为机器学习中的 核函数。
高斯分布公式(概率密度函数 PDF):
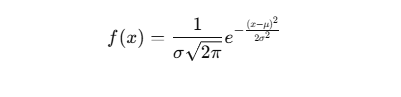
其中:
- ( \mu ) 是均值(mean)
- ( \sigma ) 是标准差(std deviation)
适用场景
✅ 概率计算:计算数据的概率分布(如正态分布)
✅ 图像处理:高斯模糊(Gaussian Blur)
✅ 机器学习:支持向量机(SVM)中的高斯核函数
✅ 异常检测:使用高斯分布计算异常概率
Python 实现
import numpy as np
def gaussian(x, mu=0, sigma=1):
return (1/(sigma * np.sqrt(2*np.pi))) * np.exp(-((x - mu)**2 / (2*sigma**2)))
x = np.linspace(-5, 5, 100)
y = gaussian(x, mu=0, sigma=1)
print(y) # 高斯分布曲线
3. 向量化算法(Vectorization)
原理
向量化算法不是单一算法,而是一种 优化计算的方法,用于 将传统的循环操作转换为向量操作,提高计算效率。
例如:
- 标量计算(非向量化):
result = []
for i in range(len(A)):
result.append(A[i] + B[i])
- 向量化计算(使用 NumPy):
result = A + B
使用 NumPy 或 GPU 进行向量化可以极大提高计算速度,特别是在大规模数据处理中。
适用场景
✅ 机器学习:向量化数据处理,提高计算效率
✅ 深度学习:GPU 计算时,批量处理数据
✅ 大数据计算:如 Pandas DataFrame 操作
Python 实现
import numpy as np
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
# 向量化加法
result = A + B
print(result) # 输出 [5, 7, 9]
4. 欧式距离(Euclidean Distance)
原理
欧式距离是计算两个点之间的直线距离的常见方法:
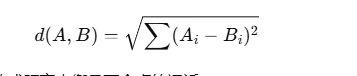
如果数据是 高维向量,可以用欧式距离来衡量两个点的远近。
适用场景
✅ KNN(K 近邻算法):计算数据点之间的距离
✅ 图像处理:计算像素间的相似度
✅ 聚类分析(K-means):用于衡量点到中心的距离
Python 实现
import numpy as np
def euclidean_distance(A, B):
return np.sqrt(np.sum((A - B) ** 2))
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
print(euclidean_distance(A, B)) # 计算欧式距离
总结对比

选择建议:
- 如果是文本或推荐系统,用 余弦相似度
- 如果是概率计算或模糊化,用 高斯算法
- 如果是大数据优化,用 向量化算法
- 如果是分类或聚类,用 欧式距离
第一版:基于 Goroutine 的并发计算
实现思路
在第一版实现中,每个候选用户的相似度计算都在一个独立的 goroutine 中执行。用户属性包括年龄、身高、学历以及标签(使用向量表示),相似度计算则采用了各维度简单的归一化计算,并将标签相似度定义为余弦相似度。最终通过加权求和得到综合相似度,再按相似度降序排序选取前 N 个匹配用户。
代码示例
package main
import (
"fmt"
"math"
"math/rand"
"sort"
"sync"
"testing"
"time"
)
// 学历枚举及映射
var EducationMap = []string{"高中", "大专", "本科", "硕士", "博士"}
// 将学历转换为数值,便于比较
func EducationToScore(edu string) int {
for i, v := range EducationMap {
if edu == v {
return i
}
}
return 0
}
// 用户结构体:包含昵称、家乡、年龄、身高、学历和标签(向量表示)
type User struct {
ID int
Nickname string
Hometown string
Age int
Height int
Education string
Tags []int // 标签:使用向量表示
}
// 生成随机用户数据
func CreateUser(id int) User {
return User{
ID: id,
Nickname: fmt.Sprintf("用户%d", id),
Hometown: fmt.Sprintf("城市%d", rand.Intn(50)),
Age: rand.Intn(30) + 18, // 年龄范围 18~47
Height: rand.Intn(50) + 150, // 身高范围 150~199
Education: EducationMap[rand.Intn(len(EducationMap))],
Tags: []int{rand.Intn(10), rand.Intn(10), rand.Intn(10)},
}
}
// 计算向量的余弦相似度(用于标签向量)
func CosineSimilarity(vec1, vec2 []int) float64 {
if len(vec1) != len(vec2) {
return 0.0
}
var dotProduct, normA, normB float64
for i := 0; i < len(vec1); i++ {
dotProduct += float64(vec1[i] * vec2[i])
normA += float64(vec1[i] * vec1[i])
normB += float64(vec2[i] * vec2[i])
}
if normA == 0 || normB == 0 {
return 0.0
}
return dotProduct / (math.Sqrt(normA) * math.Sqrt(normB))
}
// 复合相似度计算:综合年龄、身高、学历和标签
func CompositeSimilarity(target, candidate User) float64 {
// 年龄相似度
ageDiff := math.Abs(float64(target.Age - candidate.Age))
maxAgeDiff := 20.0
ageSim := math.Max(0, 1-ageDiff/maxAgeDiff)
// 身高相似度
heightDiff := math.Abs(float64(target.Height - candidate.Height))
maxHeightDiff := 20.0
heightSim := math.Max(0, 1-heightDiff/maxHeightDiff)
// 学历相似度:将学历映射为数值,再比较
eduTarget := EducationToScore(target.Education)
eduCandidate := EducationToScore(candidate.Education)
eduDiff := math.Abs(float64(eduTarget - eduCandidate))
maxEduDiff := 4.0
eduSim := math.Max(0, 1-eduDiff/maxEduDiff)
// 标签相似度(余弦相似度,值域 [0,1])
tagSim := CosineSimilarity(target.Tags, candidate.Tags)
// 设定权重(可根据实际需求调整)
wAge := 0.3
wHeight := 0.3
wEdu := 0.1
wTag := 0.3
compositeSim := wAge*ageSim + wHeight*heightSim + wEdu*eduSim + wTag*tagSim
return compositeSim
}
// 并发计算所有用户与目标用户的复合匹配分数,并返回排序后前 topN 个结果
func FindTopMatches(target User, users []User, topN int) []struct {
User User
Similarity float64
} {
type Match struct {
User User
Similarity float64
}
var matches []Match
var wg sync.WaitGroup
matchChan := make(chan Match, len(users))
// 并发计算每个候选用户的复合相似度
for _, user := range users {
wg.Add(1)
go func(u User) {
defer wg.Done()
// 跳过自己匹配自己
if u.ID == target.ID {
return
}
similarity := CompositeSimilarity(target, u)
matchChan <- Match{User: u, Similarity: similarity}
}(user)
}
// 关闭通道
go func() {
wg.Wait()
close(matchChan)
}()
// 收集匹配结果
for match := range matchChan {
matches = append(matches, match)
}
// 按匹配分数降序排序
sort.Slice(matches, func(i, j int) bool {
return matches[i].Similarity > matches[j].Similarity
})
// 取前 topN 个匹配用户
var topMatches []struct {
User User
Similarity float64
}
for i := 0; i < topN && i < len(matches); i++ {
topMatches = append(topMatches, struct {
User User
Similarity float64
}{User: matches[i].User, Similarity: matches[i].Similarity})
}
return topMatches
}
// 输出用户详细信息
func PrintUserDetails(user User) {
fmt.Printf("昵称: %s\n", user.Nickname)
fmt.Printf("家乡: %s\n", user.Hometown)
fmt.Printf("年龄: %d\n", user.Age)
fmt.Printf("身高: %dcm\n", user.Height)
fmt.Printf("学历: %s\n", user.Education)
fmt.Printf("标签: %v\n", user.Tags)
fmt.Println("---------------------------")
}
func TestUser(t *testing.T) {
// 设置随机种子
rand.Seed(time.Now().UnixNano())
timeData := time.Now()
// 创建 100 万用户
totalUsers := 1000000
users := make([]User, totalUsers)
for i := 0; i < totalUsers; i++ {
users[i] = CreateUser(i)
}
fmt.Printf("创建用户数据耗时: %s\n", time.Since(timeData))
// 选择一个目标用户进行匹配
targetUser := users[rand.Intn(totalUsers)]
fmt.Println("====== 目标用户信息 ======")
PrintUserDetails(targetUser)
// 匹配最相似的 5 个用户
start := time.Now()
matches := FindTopMatches(targetUser, users, 5)
elapsed := time.Since(start)
// 输出匹配结果(包含复合相似度)
fmt.Println("====== 匹配用户信息 ======")
for _, match := range matches {
fmt.Printf("综合相似度: %.4f\n", match.Similarity)
PrintUserDetails(match.User)
}
fmt.Printf("匹配时间: %s\n", elapsed)
}
来看一下性能
=== RUN TestUser
创建用户数据耗时: 568.6779ms
====== 目标用户信息 ======
昵称: 用户102648
家乡: 城市3
年龄: 25
身高: 185cm
学历: 硕士
标签: [8 5 3]
---------------------------
====== 匹配用户信息 ======
综合相似度: 0.9999
昵称: 用户527371
家乡: 城市46
年龄: 25
身高: 185cm
学历: 硕士
标签: [5 3 2]
---------------------------
综合相似度: 0.9985
昵称: 用户317718
家乡: 城市39
年龄: 25
身高: 185cm
学历: 硕士
标签: [7 5 2]
---------------------------
综合相似度: 0.9983
昵称: 用户677659
家乡: 城市44
年龄: 25
身高: 185cm
学历: 硕士
标签: [8 6 4]
---------------------------
综合相似度: 0.9976
昵称: 用户54358
家乡: 城市12
年龄: 25
身高: 185cm
学历: 硕士
标签: [8 4 2]
---------------------------
综合相似度: 0.9976
昵称: 用户182769
家乡: 城市22
年龄: 25
身高: 185cm
学历: 硕士
标签: [8 4 2]
---------------------------
匹配时间: 1.0862835s
--- PASS: TestUser (1.66s)
PASS
Debugger finished with the exit code 0
存在的问题
- 资源调度开销: 虽然 goroutine 很轻量,但当并发计算达到 100 万时,goroutine 的调度和上下文切换也会带来一定的性能压力。
- 内存占用: 每个 goroutine 都会占用一定的栈内存,累计下来会造成较大的内存消耗。
这些问题促使我们寻找更高效的解决方案——利用矩阵和向量化计算。
第二版:矩阵优化实现
优化思路
-
数据预处理
将候选用户的年龄、身高、学历(映射为数值)和标签数据提前整理到相应的 slice 和矩阵中。 -
向量化计算
- 对于年龄、身高和学历的相似度计算,直接采用简单循环操作即可,因计算量较小。
- 对于标签相似度,则利用 gonum 库的矩阵运算,将所有候选用户的标签数据组织成一个矩阵,再与目标用户的标签向量进行批量计算余弦相似度。
-
综合相似度与排序
将各维度相似度按照预设权重加权求和,最终选取相似度最高的前 N 个用户。
代码示例
package main
import (
"fmt"
"math"
"math/rand"
"sort"
"testing"
"time"
"gonum.org/v1/gonum/mat"
)
// 学历枚举及映射
var EducationMap = []string{"高中", "大专", "本科", "硕士", "博士"}
// 将学历转换为数值,便于比较
func EducationToScore(edu string) int {
for i, v := range EducationMap {
if edu == v {
return i
}
}
return 0
}
// 用户结构体:包含昵称、家乡、年龄、身高、学历和标签(向量表示)
type User struct {
ID int
Nickname string
Hometown string
Age int
Height int
Education string
Tags []int // 标签:使用向量表示
}
// 生成随机用户数据
func CreateUser(id int) User {
return User{
ID: id,
Nickname: fmt.Sprintf("用户%d", id),
Hometown: fmt.Sprintf("城市%d", rand.Intn(50)),
Age: rand.Intn(30) + 18, // 年龄范围 18~47
Height: rand.Intn(50) + 150, // 身高范围 150~199
Education: EducationMap[rand.Intn(len(EducationMap))],
Tags: []int{rand.Intn(10), rand.Intn(10), rand.Intn(10)},
}
}
// 输出用户详细信息
func PrintUserDetails(user User) {
fmt.Printf("昵称: %s\n", user.Nickname)
fmt.Printf("家乡: %s\n", user.Hometown)
fmt.Printf("年龄: %d\n", user.Age)
fmt.Printf("身高: %dcm\n", user.Height)
fmt.Printf("学历: %s\n", user.Education)
fmt.Printf("标签: %v\n", user.Tags)
fmt.Println("---------------------------")
}
// 使用矩阵和向量化计算综合相似度,避免为每个用户开启独立 goroutine
func FindTopMatchesMatrix(target User, users []User, topN int) []struct {
User User
Similarity float64
} {
total := len(users)
// 构建候选数据:排除目标用户自身
ages := make([]float64, 0, total)
heights := make([]float64, 0, total)
eduScores := make([]float64, 0, total)
tagsData := make([]float64, 0, total*3)
indices := make([]int, 0, total) // 保存候选用户在原数组中的下标
// 目标用户的属性
targetAge := float64(target.Age)
targetHeight := float64(target.Height)
targetEdu := float64(EducationToScore(target.Education))
targetTags := make([]float64, len(target.Tags))
var targetTagNorm float64
for i, v := range target.Tags {
targetTags[i] = float64(v)
targetTagNorm += float64(v * v)
}
targetTagNorm = math.Sqrt(targetTagNorm)
// 收集候选用户的属性
for i, u := range users {
if u.ID == target.ID {
continue
}
ages = append(ages, float64(u.Age))
heights = append(heights, float64(u.Height))
eduScores = append(eduScores, float64(EducationToScore(u.Education)))
for _, t := range u.Tags {
tagsData = append(tagsData, float64(t))
}
indices = append(indices, i)
}
n := len(ages)
// 参数设置
maxAgeDiff := 20.0
maxHeightDiff := 20.0
maxEduDiff := 4.0
ageSims := make([]float64, n)
heightSims := make([]float64, n)
eduSims := make([]float64, n)
tagSims := make([]float64, n)
// 计算年龄、身高、学历的相似度(采用向量化处理的思路,这里直接循环效率也很高)
for i := 0; i < n; i++ {
ageDiff := math.Abs(targetAge - ages[i])
ageSim := 1 - ageDiff/maxAgeDiff
if ageSim < 0 {
ageSim = 0
}
ageSims[i] = ageSim
heightDiff := math.Abs(targetHeight - heights[i])
heightSim := 1 - heightDiff/maxHeightDiff
if heightSim < 0 {
heightSim = 0
}
heightSims[i] = heightSim
eduDiff := math.Abs(targetEdu - eduScores[i])
eduSim := 1 - eduDiff/maxEduDiff
if eduSim < 0 {
eduSim = 0
}
eduSims[i] = eduSim
}
// 利用 gonum 构建候选用户标签矩阵,尺寸为 n x 3
tagMatrix := mat.NewDense(n, 3, tagsData)
// 构建目标用户标签向量
targetVec := mat.NewVecDense(len(targetTags), targetTags)
// 计算每个候选用户与目标用户标签向量的点积及归一化(余弦相似度)
for i := 0; i < n; i++ {
row := tagMatrix.RowView(i)
dp := mat.Dot(row, targetVec)
normCandidate := mat.Norm(row, 2)
if normCandidate == 0 || targetTagNorm == 0 {
tagSims[i] = 0
} else {
tagSims[i] = dp / (normCandidate * targetTagNorm)
}
}
// 综合相似度计算,设定各项权重(可根据需求调整)
wAge, wHeight, wEdu, wTag := 0.3, 0.3, 0.1, 0.3
compositeSims := make([]float64, n)
for i := 0; i < n; i++ {
compositeSims[i] = wAge*ageSims[i] + wHeight*heightSims[i] + wEdu*eduSims[i] + wTag*tagSims[i]
}
// 将计算结果与候选用户原始下标对应,并排序
type Match struct {
index int
similarity float64
}
matches := make([]Match, n)
for i := 0; i < n; i++ {
matches[i] = Match{
index: indices[i],
similarity: compositeSims[i],
}
}
sort.Slice(matches, func(i, j int) bool {
return matches[i].similarity > matches[j].similarity
})
// 取前 topN 个匹配结果
topMatches := make([]struct {
User User
Similarity float64
}, 0, topN)
for i := 0; i < topN && i < len(matches); i++ {
topMatches = append(topMatches, struct {
User User
Similarity float64
}{
User: users[matches[i].index],
Similarity: matches[i].similarity,
})
}
return topMatches
}
func TestUser(t *testing.T) {
// 设置随机种子
rand.Seed(time.Now().UnixNano())
startTime := time.Now()
// 创建 100 万用户
totalUsers := 1000000
users := make([]User, totalUsers)
for i := 0; i < totalUsers; i++ {
users[i] = CreateUser(i)
}
fmt.Printf("创建用户数据耗时: %s\n", time.Since(startTime))
// 随机选取一个目标用户进行匹配
targetUser := users[rand.Intn(totalUsers)]
fmt.Println("====== 目标用户信息 ======")
PrintUserDetails(targetUser)
// 利用矩阵优化方法匹配最相似的 5 个用户
start := time.Now()
matches := FindTopMatchesMatrix(targetUser, users, 5)
elapsed := time.Since(start)
// 输出匹配结果
fmt.Println("====== 匹配用户信息 ======")
for _, match := range matches {
fmt.Printf("综合相似度: %.4f\n", match.Similarity)
PrintUserDetails(match.User)
}
fmt.Printf("匹配时间: %s\n", elapsed)
}
性能
GOROOT=D:\software\go\go #gosetup
GOPATH=D:\software\go\project #gosetup
D:\software\go\go\bin\go.exe test -c -o C:\Users\Administrator\AppData\Local\JetBrains\GoLand2024.1\tmp\GoLand\___TestUser_in_wann_redmoon.test.exe -gcflags "all=-N -l" wann-redmoon #gosetup
D:\software\go\go\bin\go.exe tool test2json -t "D:\software\goland\GoLand 2024.1.4\plugins\go-plugin\lib\dlv\windows\dlv.exe" --listen=127.0.0.1:60666 --headless=true --api-version=2 --check-go-version=false --only-same-user=false exec C:\Users\Administrator\AppData\Local\JetBrains\GoLand2024.1\tmp\GoLand\___TestUser_in_wann_redmoon.test.exe -- -test.v -test.paniconexit0 -test.run ^\QTestUser\E$ #gosetup
API server listening at: 127.0.0.1:60666
=== RUN TestUser
创建用户数据耗时: 575.0731ms
====== 目标用户信息 ======
昵称: 用户987294
家乡: 城市46
年龄: 26
身高: 155cm
学历: 大专
标签: [5 6 0]
---------------------------
====== 匹配用户信息 ======
综合相似度: 1.0000
昵称: 用户795742
家乡: 城市18
年龄: 26
身高: 155cm
学历: 大专
标签: [5 6 0]
---------------------------
综合相似度: 0.9998
昵称: 用户513362
家乡: 城市10
年龄: 26
身高: 155cm
学历: 大专
标签: [8 9 0]
---------------------------
综合相似度: 0.9988
昵称: 用户170804
家乡: 城市41
年龄: 26
身高: 155cm
学历: 大专
标签: [1 1 0]
---------------------------
综合相似度: 0.9976
昵称: 用户753184
家乡: 城市29
年龄: 26
身高: 155cm
学历: 大专
标签: [5 6 1]
---------------------------
综合相似度: 0.9973
昵称: 用户524932
家乡: 城市9
年龄: 26
身高: 155cm
学历: 大专
标签: [7 7 1]
---------------------------
匹配时间: 554.8242ms
--- PASS: TestUser (1.13s)
PASS
Debugger finished with the exit code 0
从结果来看:这套方案,无论是在内存上还是在性能上都有了质的提升。矩阵优化前,1百万个用户,时间消耗1秒;优化后,时间消耗0.5秒。整体提升一倍左右。
迭代过程回顾
-
初始方案(第一版):
- 直接为每个候选用户开启 goroutine 计算相似度。
- 代码结构清晰,但在百万级用户下会引入过多的并发调度和内存开销。
-
发现瓶颈:
- 尽管 goroutine 轻量,但调度大量并发任务仍然会带来不小的性能负担。
- 同时,每个 goroutine 都要重复进行相似度计算的循环,部分操作存在冗余。
-
优化思路转变(第二版):
- 将用户数据预先整理成 slice 和矩阵,利用矩阵运算批量计算标签相似度。
- 其他属性(年龄、身高、学历)的相似度计算依旧使用简单的循环,但减少了 goroutine 的数量。
- 利用 gonum 库进行高效的向量化计算,大幅降低了运算和内存开销。
-
最终成果:
- 第二版在百万级用户匹配上有显著性能提升。
- 代码更加简洁,计算逻辑更清晰,易于扩展和调试。
性能对比与实际效果
通过矩阵优化:
- 内存占用更低: 不再为每个候选用户分配独立的 goroutine,而是批量计算。
- 计算效率更高: 向量化计算能充分利用底层优化的数学库,标签相似度部分的运算速度提升显著。
- 扩展性更好: 当用户数量进一步增加时,矩阵运算方式能更好地支撑大规模数据处理。
总结
在大规模用户匹配场景中,从基于并发的逐条计算到矩阵优化的向量化计算是一个重要的优化过程。第一版虽然简单直接,但在百万级数据下会受到调度和内存开销的限制;而第二版通过矩阵运算不仅降低了资源消耗,还显著提升了计算效率。希望这篇文章能为你在大数据匹配与优化方面提供一些思路和实践经验。
在进行千万级别用户测试来看看吧
方案一
=== RUN TestUser
创建用户数据耗时: 5.5234411s
====== 目标用户信息 ======
昵称: 用户4583640
家乡: 城市23
年龄: 40
身高: 167cm
学历: 本科
标签: [6 2 5]
---------------------------
====== 匹配用户信息 ======
综合相似度: 1.0000
昵称: 用户4857464
家乡: 城市41
年龄: 40
身高: 167cm
学历: 本科
标签: [6 2 5]
---------------------------
综合相似度: 1.0000
昵称: 用户9763239
家乡: 城市19
年龄: 40
身高: 167cm
学历: 本科
标签: [6 2 5]
---------------------------
综合相似度: 0.9999
昵称: 用户8764945
家乡: 城市32
年龄: 40
身高: 167cm
学历: 本科
标签: [9 3 8]
---------------------------
综合相似度: 0.9998
昵称: 用户5400883
家乡: 城市29
年龄: 40
身高: 167cm
学历: 本科
标签: [9 3 7]
---------------------------
综合相似度: 0.9998
昵称: 用户9248579
家乡: 城市43
年龄: 40
身高: 167cm
学历: 本科
标签: [9 3 7]
---------------------------
匹配时间: 17.4290938s
--- PASS: TestUser (22.96s)
PASS
Debugger finished with the exit code 0
方案二
=== RUN TestUser
创建用户数据耗时: 5.6832104s
====== 目标用户信息 ======
昵称: 用户3920613
家乡: 城市29
年龄: 31
身高: 151cm
学历: 本科
标签: [9 1 5]
---------------------------
====== 匹配用户信息 ======
综合相似度: 0.9999
昵称: 用户2266856
家乡: 城市5
年龄: 31
身高: 151cm
学历: 本科
标签: [7 1 4]
---------------------------
综合相似度: 0.9999
昵称: 用户4350570
家乡: 城市3
年龄: 31
身高: 151cm
学历: 本科
标签: [7 1 4]
---------------------------
综合相似度: 0.9999
昵称: 用户1876841
家乡: 城市26
年龄: 31
身高: 151cm
学历: 本科
标签: [7 1 4]
---------------------------
综合相似度: 0.9997
昵称: 用户4560014
家乡: 城市4
年龄: 31
身高: 151cm
学历: 本科
标签: [8 1 4]
---------------------------
综合相似度: 0.9996
昵称: 用户8111471
家乡: 城市9
年龄: 31
身高: 151cm
学历: 本科
标签: [8 1 5]
---------------------------
匹配时间: 6.4763178s
--- PASS: TestUser (12.17s)
PASS
Debugger finished with the exit code 0
由此可见,数据量越大,矩阵效果越明显
矩阵+协程
如果我们把矩阵和协程结合会碰撞出怎样的火花呢?
// FindTopMatchesMatrixConcurrent 利用矩阵优化,并发计算候选用户与目标用户的综合相似度,
// 限制最多同时启用 1000 个协程。
func FindTopMatchesMatrixConcurrent(target User, users []User, topN int) []struct {
User User
Similarity float64
} {
// 预处理:将候选用户数据(排除目标用户)整理到 slice 中
var ages []float64
var heights []float64
var eduScores []float64
var tagsData []float64 // 将候选用户标签扁平化,每个用户有3个连续的数值
var indices []int // 保存候选用户在原 users 数组中的下标
for i, u := range users {
if u.ID == target.ID {
continue
}
ages = append(ages, float64(u.Age))
heights = append(heights, float64(u.Height))
eduScores = append(eduScores, float64(EducationToScore(u.Education)))
for _, t := range u.Tags {
tagsData = append(tagsData, float64(t))
}
indices = append(indices, i) // 保存原始下标
}
n := len(ages)
if n == 0 {
return nil
}
// 预计算目标用户属性
targetAge := float64(target.Age)
targetHeight := float64(target.Height)
targetEdu := float64(EducationToScore(target.Education))
targetTags := make([]float64, len(target.Tags))
var targetTagNorm float64
for i, v := range target.Tags {
targetTags[i] = float64(v)
targetTagNorm += float64(v * v)
}
targetTagNorm = math.Sqrt(targetTagNorm)
// 参数设置
maxAgeDiff := 20.0
maxHeightDiff := 20.0
maxEduDiff := 4.0
wAge, wHeight, wEdu, wTag := 0.3, 0.3, 0.1, 0.3
// 定义 worker 处理的结果结构
type matchResult struct {
index int // 原始 users 数组中的下标
similarity float64 // 综合相似度
}
// 创建 job 和结果通道
jobs := make(chan int, n) // job 传递候选用户在预处理数组中的索引
results := make(chan matchResult, n)
// 限制最大协程数为 1000(如果候选数少于 1000,则使用 n 个)
workerCount := 1000
if n < workerCount {
workerCount = n
}
var wg sync.WaitGroup
// Worker 函数:不断从 jobs 通道中取任务计算相似度
worker := func() {
defer wg.Done()
for idx := range jobs {
// 从预处理数组中取出候选用户属性
candidateAge := ages[idx]
candidateHeight := heights[idx]
candidateEdu := eduScores[idx]
// 每个用户的标签在 tagsData 中连续存放:索引范围为 [idx*3, idx*3+3)
base := idx * 3
candidateTags := tagsData[base : base+3]
// 计算年龄相似度
ageDiff := math.Abs(targetAge - candidateAge)
ageSim := 1 - ageDiff/maxAgeDiff
if ageSim < 0 {
ageSim = 0
}
// 计算身高相似度
heightDiff := math.Abs(targetHeight - candidateHeight)
heightSim := 1 - heightDiff/maxHeightDiff
if heightSim < 0 {
heightSim = 0
}
// 计算学历相似度
eduDiff := math.Abs(targetEdu - candidateEdu)
eduSim := 1 - eduDiff/maxEduDiff
if eduSim < 0 {
eduSim = 0
}
// 计算标签相似度(余弦相似度)
dot := 0.0
tagNorm := 0.0
for i := 0; i < len(candidateTags); i++ {
dot += candidateTags[i] * targetTags[i]
tagNorm += candidateTags[i] * candidateTags[i]
}
tagNorm = math.Sqrt(tagNorm)
tagSim := 0.0
if tagNorm != 0 && targetTagNorm != 0 {
tagSim = dot / (tagNorm * targetTagNorm)
}
// 综合相似度计算
compositeSim := wAge*ageSim + wHeight*heightSim + wEdu*eduSim + wTag*tagSim
// 结果中保存原始 users 数组的下标
results <- matchResult{
index: indices[idx],
similarity: compositeSim,
}
}
}
// 启动 worker 协程
wg.Add(workerCount)
for i := 0; i < workerCount; i++ {
go worker()
}
// 将所有候选任务放入 jobs 通道
for i := 0; i < n; i++ {
jobs <- i
}
close(jobs)
// 等待所有 worker 完成计算,然后关闭结果通道
wg.Wait()
close(results)
// 收集所有匹配结果
var matches []matchResult
for m := range results {
matches = append(matches, m)
}
// 按综合相似度降序排序
sort.Slice(matches, func(i, j int) bool {
return matches[i].similarity > matches[j].similarity
})
// 取出前 topN 个匹配结果,并还原为完整的用户信息
var topMatches []struct {
User User
Similarity float64
}
for i := 0; i < topN && i < len(matches); i++ {
topMatches = append(topMatches, struct {
User User
Similarity float64
}{
User: users[matches[i].index],
Similarity: matches[i].similarity,
})
}
return topMatches
}
番外篇:go协程 VS java线程
Go 的 goroutine 与 Java 线程相比具有非常轻量的特性,因此在相同硬件条件下,启动 1 百万个 goroutine 对程序的内存和上下文切换压力远低于启动 1 百万个 Java 线程。
协程远大于线程主要原因
-
内存占用:
- Goroutine: 每个 goroutine 初始栈内存通常只有几 KB(大约 2KB 左右),且可以按需动态增长。这样即使启动大量 goroutine,总体内存占用也非常低。
- Java 线程: Java 的线程通常是操作系统级线程,每个线程的栈大小往往在 1MB 或更多,这使得启动大量线程会迅速耗尽内存资源。
-
调度机制:
- Goroutine: Go 的调度器使用 M:N 调度,将大量 goroutine 映射到相对较少的操作系统线程上,这极大降低了上下文切换的开销。
- Java 线程: Java 的线程由操作系统直接管理,上下文切换和线程调度开销较大,难以支撑百万级别的并发线程。
1 百万个 Goroutine 的程序压力
-
低内存压力:
如果每个 goroutine 只执行简单任务(例如等待 I/O 或简单运算),1 百万个 goroutine 的内存占用通常只需要几 MB 到几十 MB,不会对系统造成严重压力。 -
调度效率:
由于 goroutine 调度器能高效地管理和调度大量任务,即使活跃的 goroutine 数量较多,也能保持较高的调度效率。当然,如果所有 goroutine 同时进行 CPU 密集型操作,可能会引起一定的竞争,但总体开销依然远低于同数量级的 Java 线程。 -
实践案例:
在许多 Go 应用和 benchmark 中,开发者经常展示启动数百万个 goroutine 而程序仍能流畅运行的场景,这验证了 Go 在高并发场景下的出色性能。
总结
启用 1 百万个 goroutine 在大多数场景下是可行且高效的,内存和调度的压力远小于同样数量的 Java 线程。不过,具体性能表现还需根据每个 goroutine 的实际工作负载来评估。如果每个 goroutine 都有较重的计算或阻塞操作,那么整体性能也可能受到影响,需要进行合理的设计和调度优化。
方案二矩阵优化代码解析
代码结构分析
-
定义用户结构体
User- 包含
昵称、家乡、年龄、身高、学历、标签(兴趣向量)等信息。
- 包含
-
生成随机用户
CreateUser- 生成 100 万个随机用户(年龄、身高、学历、标签等随机分布)。
-
核心匹配算法
FindTopMatchesMatrix- 计算目标用户和候选用户之间的综合相似度。
- 采用向量化计算提高性能,避免单独 goroutine 计算带来的开销。
- 计算 4 种相似度:
- 年龄相似度
- 身高相似度
- 学历相似度
- 兴趣标签相似度(使用余弦相似度)
- 结合权重
wAge, wHeight, wEdu, wTag计算最终匹配度。
-
测试函数
TestUser- 生成 100 万用户,选取一个目标用户,找出最相似的 5 个用户,并打印匹配结果。
匹配算法分析
1. 计算年龄相似度
公式:

- 目标:年龄差越小,相似度越高。
- 若差异大于 20 岁,则设为 0。
ageDiff := math.Abs(targetAge - ages[i])
ageSim := 1 - ageDiff/maxAgeDiff
if ageSim < 0 {
ageSim = 0
}
2. 计算身高相似度
公式:

- 目标:身高差越小,相似度越高。
- 若差异大于 20cm,则设为 0。
heightDiff := math.Abs(targetHeight - heights[i])
heightSim := 1 - heightDiff/maxHeightDiff
if heightSim < 0 {
heightSim = 0
}
3. 计算学历相似度
公式:

- 目标:学历差越小,相似度越高。
- 若差异大于 4 个学历级别,则设为 0。
eduDiff := math.Abs(targetEdu - eduScores[i])
eduSim := 1 - eduDiff/maxEduDiff
if eduSim < 0 {
eduSim = 0
}
学历映射:
- "高中" → 0
- "大专" → 1
- "本科" → 2
- "硕士" → 3
- "博士" → 4
4. 计算兴趣标签相似度(余弦相似度)
使用 gonum 进行矩阵计算,避免手写循环,提高计算速度。
余弦相似度公式
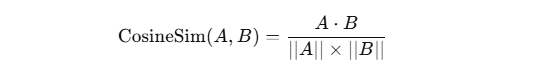
其中:

实现
tagMatrix := mat.NewDense(n, 3, tagsData) // 候选用户的标签矩阵
targetVec := mat.NewVecDense(len(targetTags), targetTags) // 目标用户的标签向量
for i := 0; i < n; i++ {
row := tagMatrix.RowView(i) // 取出候选用户的标签向量
dp := mat.Dot(row, targetVec) // 计算点积
normCandidate := mat.Norm(row, 2) // 计算候选用户的 L2 范数
if normCandidate == 0 || targetTagNorm == 0 {
tagSims[i] = 0
} else {
tagSims[i] = dp / (normCandidate * targetTagNorm) // 计算余弦相似度
}
}
作用:
- 标签越相似,点积越大,相似度越高。
5. 计算综合相似度
综合 4 种相似度,并设定不同的权重:
wAge, wHeight, wEdu, wTag := 0.3, 0.3, 0.1, 0.3
for i := 0; i < n; i++ {
compositeSims[i] = wAge*ageSims[i] + wHeight*heightSims[i] + wEdu*eduSims[i] + wTag*tagSims[i]
}
调整权重的影响:
- 增加
wTag:兴趣标签更重要。- 增加
wAge:年龄更重要。
6. 排序并选出最优匹配
sort.Slice(matches, func(i, j int) bool {
return matches[i].similarity > matches[j].similarity
})
按综合相似度降序排列,取前
topN个。
7. 代码性能优化点
-
去掉 Goroutine,改用向量化计算
gonum提供了矩阵计算,可利用 SIMD 加速,提高计算速度。
-
避免多次转换数据结构
- 预先构建
tagsData,避免每次循环读取用户Tags。
- 预先构建
-
降低循环嵌套
- 计算属性相似度时,避免冗余计算。
总结
✅ 年龄、身高、学历、兴趣标签 4 维度匹配
✅ 矩阵计算加速匹配,提高性能
✅ 基于权重调整相似度计算,灵活适配需求
✅ 大规模数据(100 万用户)依然能快速匹配
适用于社交推荐、相亲匹配、人才筛选等场景 🚀
评论区